Consider the following function, which is the product of a certain pair of binomial coefficients:
![\[f(x) := \binom{x}{a}\binom{X-x}{b}.\]](http://cmaclaurin.com/cosmos/wp-content/ql-cache/quicklatex.com-1c69da7feadf7542bab4557bbee83d88_l3.png "Rendered by QuickLaTeX.com")
We take a, b, X >> 1 to be constants, and x to have domain [a – 1, X – b + 1] which implies X > a + b – 2 at least. As usual  , and this is extended beyond integer values by replacing each factorial with a Gamma function. Note the independent variable x appears in the upper entries of the binomial coefficients. Curiously, from inspection f is well-approximated by a gaussian curve. To gain some insight, for integer values of the parameters f is the polynomial:
, and this is extended beyond integer values by replacing each factorial with a Gamma function. Note the independent variable x appears in the upper entries of the binomial coefficients. Curiously, from inspection f is well-approximated by a gaussian curve. To gain some insight, for integer values of the parameters f is the polynomial:
![\[(a! b!)^{-1}x(x-1)\cdots(x-a+1)\cdot(X-b+1-x)\cdots(X-x).\]](http://cmaclaurin.com/cosmos/wp-content/ql-cache/quicklatex.com-b20d4e7b8bc3483c861c39a29b20c96f_l3.png "Rendered by QuickLaTeX.com")
This has many zeroes, and sometimes oscillates wildly in between them, hence the domain of x specified earlier.
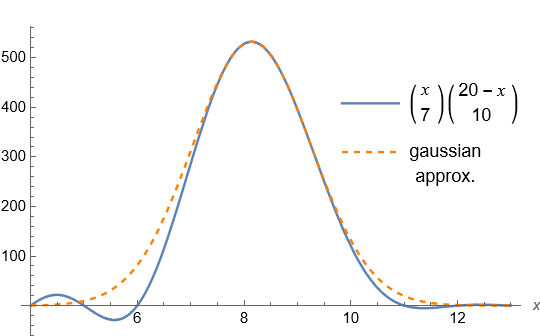
Now the usual approximations to a single binomial coefficient (actually, binomial distribution) are not helpful here. For example the de Moivre–Laplace approximation is a gaussian in terms of the lower entry in the binomial coefficient, whereas our x is in the upper entries. More promising is the approximation as a Poisson distribution, which leads to a polynomial which is itself gaussian-like, and motivated the previous post incidentally. However we proceed from first principles, by estimating the centre point and the second derivative there.
At the (central) maximum of f, the slope is zero. In general the derivative is  , where the H’s are called harmonic numbers. There may not exist any simple explicit expression for the turning points. Instead, the ratio of nearby points is comparatively simple:
, where the H’s are called harmonic numbers. There may not exist any simple explicit expression for the turning points. Instead, the ratio of nearby points is comparatively simple:
![\[\frac{f(x-1/2)}{f(x+1/2)} = \frac{(x-a+1/2)(X+1/2-x)}{(x+1/2)(X-b+1/2-x)},\]](http://cmaclaurin.com/cosmos/wp-content/ql-cache/quicklatex.com-57dd3410e47df89c49bba1c3de59ad63_l3.png "Rendered by QuickLaTeX.com")
using the properties of the binomial coefficient. The derivative is approximately zero where this ratio is unity, which occurs at:
![\[x_0 := \frac{2aX+a-b}{2(a+b)}.\]](http://cmaclaurin.com/cosmos/wp-content/ql-cache/quicklatex.com-e1e66503da60cec1c6fbc07436179f21_l3.png "Rendered by QuickLaTeX.com")
This should be a close estimate for the central turning point. [To do better, substitute specific numbers for the parameters, and solve numerically.] It is typically not an integer. Our sought-for gaussian has form  . We set the height
. We set the height  . Only the width remains to be determined. The gaussian’s second derivative evaluated at its centre point is
. Only the width remains to be determined. The gaussian’s second derivative evaluated at its centre point is  . On the other hand:
. On the other hand:
![\[f''(x) = f'(x)^2/f(x) - (H_x^{(2)}-H_{x-a}^{(2)}+H_{X-x}^{(2)}-H_{X-b-x}^{(2)})f(x),\]](http://cmaclaurin.com/cosmos/wp-content/ql-cache/quicklatex.com-7ad361f0313f7ef917aaff2215d6ae89_l3.png "Rendered by QuickLaTeX.com")
which uses the so-called harmonic numbers of order 2, and I incorporate the function and its derivative (both given earlier) for brevity of the expression. Matching the results at  yields the variance parameter
yields the variance parameter  :
:
![\[\sigma^{-2} := H_{x_0}^{(2)}-H_{x_0-a}^{(2)}+H_{X-x_0}^{(2)}-H_{X-b-x_0}^{(2)},\]](http://cmaclaurin.com/cosmos/wp-content/ql-cache/quicklatex.com-ead1aeb4d9408b154175be6911c0ad75_l3.png "Rendered by QuickLaTeX.com")
using  . (At large values the series
. (At large values the series  may give insight into the above.) But alternatively, we can approximate the second derivative using elementary operations. By sampling the function at
may give insight into the above.) But alternatively, we can approximate the second derivative using elementary operations. By sampling the function at  , , and
, , and  say, a “finite differences” approach gives approximate derivatives. We can use the simple ratio formula obtained earlier to reduce the sampling to one or two points only, which might gain some insight along the way (though I currently wonder if this is a dead end…).
say, a “finite differences” approach gives approximate derivatives. We can use the simple ratio formula obtained earlier to reduce the sampling to one or two points only, which might gain some insight along the way (though I currently wonder if this is a dead end…).
Now  , which becomes:
, which becomes:
![\[\frac{2C(a+b)^3}{(2aX+a-b)(2bX-2b^2-2ab+a+3b)},\]](http://cmaclaurin.com/cosmos/wp-content/ql-cache/quicklatex.com-246c69ac64e3e9b91c1b8ecff72861e3_l3.png "Rendered by QuickLaTeX.com")
after using the ratio formula to obtain  in terms of C. Similarly it turns out
in terms of C. Similarly it turns out  is the negative of the above expression, but with a and b interchanged. Then a second derivative is:
is the negative of the above expression, but with a and b interchanged. Then a second derivative is:  , but the combined expression does not simplify further so I won’t write it out. The last step is to set
, but the combined expression does not simplify further so I won’t write it out. The last step is to set  , which is different to the earlier choice.
, which is different to the earlier choice.
A slightly different approach uses  , which may be expressed in terms of another sampled point
, which may be expressed in terms of another sampled point  . Similarly
. Similarly  . The estimate for the second derivative follows, then later:
. The estimate for the second derivative follows, then later:
![\[\hat\sigma^2 := \frac{-2C(aX-b)(bX+a+2b)(bX-b^2-ab+a+2b)(aX-a^2-ab-b)}{E(a+b)^6}.\]](http://cmaclaurin.com/cosmos/wp-content/ql-cache/quicklatex.com-26104a688f522ab5ac0d8b4cead8903b_l3.png "Rendered by QuickLaTeX.com")
The expression is a little simpler in this approach, but at the cost of a second sample point. The use of  and
and  instead leads to the same result.
instead leads to the same result.