Suppose you have an axially symmetric vector field. Can we define an affine connection which keeps the vectors “parallel”, under rotation about the axis? For example, we wish the vectors illustrated below to get parallel-transported around the circle:

Take Minkowski spacetime in cylindrical coordinates  , with metric
, with metric  , and consider a vector field
, and consider a vector field  whose components are independent of
whose components are independent of  :
:
![\[u^\mu = (A{\scriptstyle(t,r,z)},B{\scriptstyle(t,r,z)},C{\scriptstyle(t,r,z)},D{\scriptstyle(t,r,z)}).\]](http://cmaclaurin.com/cosmos/wp-content/ql-cache/quicklatex.com-7ea388ebf0985f0cec1a8c32889237d1_l3.png "Rendered by QuickLaTeX.com")
The covariant derivative in the tangential direction  has components:
has components:
![\[(\nabla_{\partial_\phi}\mathbf u)^\alpha = \Big(0,-rC{\scriptstyle(t,r,z)},\frac{B{\scriptstyle(t,r,z)}}{r},0\Big).\]](http://cmaclaurin.com/cosmos/wp-content/ql-cache/quicklatex.com-37a9a26220f7818ac58dc9f7fce4bb48_l3.png "Rendered by QuickLaTeX.com")
We want this to vanish, but first a quick recap (Lee  §4, 5). Recall a connection is defined by
§4, 5). Recall a connection is defined by  , in terms of our coordinate vector frame
, in terms of our coordinate vector frame  . This extends to a covariant derivative of arbitrary vectors and tensors, also denoted “
. This extends to a covariant derivative of arbitrary vectors and tensors, also denoted “ ”. The derivative of above assumed the Levi–Civita connection, which is inherited from the metric: it is the unique symmetric, metric-compatible connection. In that case the set of
”. The derivative of above assumed the Levi–Civita connection, which is inherited from the metric: it is the unique symmetric, metric-compatible connection. In that case the set of  are called Christoffel symbols, but in general they are called connection coefficients.
are called Christoffel symbols, but in general they are called connection coefficients.
The offending Christoffel symbols which prevent our vector field from being parallel-transported are:  and
and  . But we are free to simply define a new connection for which these vanish:
. But we are free to simply define a new connection for which these vanish:  ! Given a frame, any set of smooth functions
! Given a frame, any set of smooth functions  yields a valid connection (Lee, Lemma 4.10). It is natural to hold on to the other Christoffel symbols, to accord whatever respect remains for the metric. In fact only one is nonzero,
yields a valid connection (Lee, Lemma 4.10). It is natural to hold on to the other Christoffel symbols, to accord whatever respect remains for the metric. In fact only one is nonzero,  . To set this to zero would essentially deny the increase in circumference with the radius. Incidentally, even with keeping
. To set this to zero would essentially deny the increase in circumference with the radius. Incidentally, even with keeping  , the new connection is flat, meaning its associated Riemann curvature tensor vanishes.
, the new connection is flat, meaning its associated Riemann curvature tensor vanishes.
The new connection may be expressed as the Levi–Civita one with a bilinear correction:
![\[\tilde\nabla_{\mathbf v}\mathbf u = \nabla_{\mathbf v}\mathbf u - \big( \frac{1}{r}\partial_\phi\otimes d\phi\otimes dr - r\partial_r\otimes d\phi\otimes d\phi \big) (\mathbf v,\mathbf u),\]](http://cmaclaurin.com/cosmos/wp-content/ql-cache/quicklatex.com-6ab2d0003a0d0d18f82b5f20d1b65d75_l3.png "Rendered by QuickLaTeX.com")
where  and are arbitrary vectors, to be substituted into the 2nd and 3rd slots respectively of the (1,2)-tensor in parentheses. This is much simpler than it looks, as the terms just pick out
and are arbitrary vectors, to be substituted into the 2nd and 3rd slots respectively of the (1,2)-tensor in parentheses. This is much simpler than it looks, as the terms just pick out  and -components, and return basis vectors. Equivalently, the correction may be written
and -components, and return basis vectors. Equivalently, the correction may be written  , where the angle brackets mean contraction of a 1-form and vector. Notice from here and the two “offending” Christoffel symbols mentioned earlier, that only (the component of) the derivative in the –direction is affected.
, where the angle brackets mean contraction of a 1-form and vector. Notice from here and the two “offending” Christoffel symbols mentioned earlier, that only (the component of) the derivative in the –direction is affected.
These expressions obscure some beautiful symmetry. Let’s raise one index and lower another, in the correction term:
![\[\tilde\nabla_{\mathbf v}\mathbf u = \nabla_{\mathbf v}\mathbf u - \frac{1}{r}\langle d\phi,\mathbf v\rangle \cdot (2\partial_r\wedge\partial_\phi)\lrcorner\mathbf u^\flat.\]](http://cmaclaurin.com/cosmos/wp-content/ql-cache/quicklatex.com-4cfd359f19b5c843a7868383ac066f96_l3.png "Rendered by QuickLaTeX.com")
Here  is a wedge product,
is a wedge product,  is just the 1-form with components
is just the 1-form with components  , and “
, and “ ” is a contraction. The correction’s components are simply
” is a contraction. The correction’s components are simply  . This is a vector, even though some lowered indices appear in the expression. The correction is just a rotation in the
. This is a vector, even though some lowered indices appear in the expression. The correction is just a rotation in the  –plane! From inspection of the diagram, this is unsurprising.
–plane! From inspection of the diagram, this is unsurprising.
This is analogous to Fermi–Walker transport. Given a worldline, this corrects the (Levi–Civita connection) time-derivative  by a rotation in the plane spanned by and the 4-acceleration vector
by a rotation in the plane spanned by and the 4-acceleration vector  . Under Fermi–Walker transport, orthonormal frames stay orthonormal over time, and their orientation agrees with gyroscopes. For both our connection and the Fermi-Walker derivative, there is a preferred differentiation direction, along which a rotation is added to the Levi-Civita derivative.
. Under Fermi–Walker transport, orthonormal frames stay orthonormal over time, and their orientation agrees with gyroscopes. For both our connection and the Fermi-Walker derivative, there is a preferred differentiation direction, along which a rotation is added to the Levi-Civita derivative.
I previously wrote about a connection for a spherically symmetric vector field. This has been a good learning experience about connections other than Levi-Civita. Many of us completed general relativity courses in which the curvature quantities were merely formulae with no intuitive understanding. However questions from mathematicians like: “Which connection are you using?” prompted me to learn more. (At least I have never been asked which differential structure I am using, nor which point-set topology, which is fortunate for all involved. 🙂 ) There are various physically-motivated connections defined in research paper ") §2. I intend to apply this to the rotating disc, and to an observer field in Schwarzschild spacetime. Also, I accidentally came across Rothman+ 2001 about parallel transport in Schwarzschild spacetime, with numerous followup papers by various authors. All of this struck me again with a sense of fascination about curvature: how rich and deep it is.
§2. I intend to apply this to the rotating disc, and to an observer field in Schwarzschild spacetime. Also, I accidentally came across Rothman+ 2001 about parallel transport in Schwarzschild spacetime, with numerous followup papers by various authors. All of this struck me again with a sense of fascination about curvature: how rich and deep it is.
 , interpreted as an operator on vectors. Here we re-express this well known fact using a general, index-free, coordinate-independent, 4-vector notation, which is valid locally in curved spacetime.
, interpreted as an operator on vectors. Here we re-express this well known fact using a general, index-free, coordinate-independent, 4-vector notation, which is valid locally in curved spacetime.![\[\Lambda^\mu_{\hphantom\mu\nu} = \begin{pmatrix} \gamma & -\beta\gamma & 0 & 0 \\ -\beta\gamma & \gamma & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 \end{pmatrix}.\]](http://cmaclaurin.com/cosmos/wp-content/ql-cache/quicklatex.com-68d50c5187fbde99d25e739c68fc6b31_l3.png "Rendered by QuickLaTeX.com")
 -direction by speed
-direction by speed  or
or  . It maps an arbitrary vector
. It maps an arbitrary vector  to
to  . Numerous authors generalise to arbitrary boost directions, such as Møller
. Numerous authors generalise to arbitrary boost directions, such as Møller  and
and  . The arrows signify 3-dimensional vectors,
. The arrows signify 3-dimensional vectors,  is the position in 3-space, and
is the position in 3-space, and  is the relative 3-velocity. The space part uses beautiful, coordinate-independent vector language. However the time part requires privileged coordinates adapted to the observers. We will derive a 4-vector analogue.
is the relative 3-velocity. The space part uses beautiful, coordinate-independent vector language. However the time part requires privileged coordinates adapted to the observers. We will derive a 4-vector analogue. (located at the same point, if in curved spacetime). They are related by the Lorentz boost:
(located at the same point, if in curved spacetime). They are related by the Lorentz boost:![\[\mathbf n = \gamma(\mathbf u+\beta\hat{\vec{\mathbf n}}) = \gamma(\mathbf u+\vec{\mathbf n}),\]](http://cmaclaurin.com/cosmos/wp-content/ql-cache/quicklatex.com-976c71d70f0acb9ee6cbc95904521535_l3.png "Rendered by QuickLaTeX.com")
 , the unit vector
, the unit vector  points in the boost direction, and
points in the boost direction, and  is the relative velocity. This is the 4-vector analogue of the familiar coordinate boost
is the relative velocity. This is the 4-vector analogue of the familiar coordinate boost  . Combined with the space boost given shortly, this forms a local Lorentz transformation. While the plus sign makes the above appear an inverse boost, this is only because vectors (as whole entities) transform inversely to coordinates. Rearranging:
. Combined with the space boost given shortly, this forms a local Lorentz transformation. While the plus sign makes the above appear an inverse boost, this is only because vectors (as whole entities) transform inversely to coordinates. Rearranging:![\[\vec{\mathbf n} = \gamma^{-1}\mathbf n - \mathbf u.\]](http://cmaclaurin.com/cosmos/wp-content/ql-cache/quicklatex.com-bdd7d26ffdb82faf889f9e8ab7d7dd7a_l3.png "Rendered by QuickLaTeX.com")
 . Now, the vector analogue of the usual boosted spatial coordinate
. Now, the vector analogue of the usual boosted spatial coordinate  is
is  . After multiplying by
. After multiplying by ![\[\vec{\mathbf n} \mapsto \gamma(\vec{\mathbf n} + \beta^2\mathbf u) = \mathbf n - \gamma^{-1}\mathbf u = -\vec{\mathbf u}.\]](http://cmaclaurin.com/cosmos/wp-content/ql-cache/quicklatex.com-24caef02e693288595a74ec2fcdda030_l3.png "Rendered by QuickLaTeX.com")
 . So we have the boost’s action on the orthogonal vectors
. So we have the boost’s action on the orthogonal vectors  , plus it is the identity on the 2-dimensional spatial plane orthogonal to both, hence:
, plus it is the identity on the 2-dimensional spatial plane orthogonal to both, hence:![\[\begin{aligned} \Lambda^\mu_{\hphantom\mu\nu} &= (g^\mu_{\hphantom\mu\nu} + u^\mu u_\nu -\beta^{-2}\vec n^\mu \vec n_\nu) - n^\mu u_\nu -\beta^{-2}\vec u^\mu \vec n_\nu \\ &= g^\mu_{\hphantom\mu\nu} + (u^\mu-n^\mu)u_\nu + \frac{\gamma}{\gamma+1}(u^\mu + n^\mu)\vec n_\nu, \end{aligned}\]](http://cmaclaurin.com/cosmos/wp-content/ql-cache/quicklatex.com-a7233c2009bc79ed85bc9b2a7ddba39d_l3.png "Rendered by QuickLaTeX.com")
 and
and  . It is a good exercise to check the contractions with
. It is a good exercise to check the contractions with  ,
,  , or any
, or any  orthogonal to both. In index-free notation,
orthogonal to both. In index-free notation,![\[\boldsymbol\Lambda = \mathbf g^{\sharp\flat} + (\mathbf u-\mathbf n)\otimes\mathbf u^\flat +\frac{\gamma}{\gamma+1}(\mathbf u+\mathbf n)\otimes\vec{\mathbf n}^\flat.\]](http://cmaclaurin.com/cosmos/wp-content/ql-cache/quicklatex.com-78c71818ca462d53d5ae51b238af0e07_l3.png "Rendered by QuickLaTeX.com")
![\[\boldsymbol\Lambda = \mathbf g^{\sharp\flat} + \big((1-\gamma)\mathbf u - \gamma\vec{\mathbf n})\otimes\mathbf u^\flat + \big(\gamma\mathbf u + \frac{\gamma^2}{\gamma+1}\vec{\mathbf n}\big)\otimes\vec{\mathbf n}^\flat,\]](http://cmaclaurin.com/cosmos/wp-content/ql-cache/quicklatex.com-492a6196c1ba63ee4540ebee9e5d249f_l3.png "Rendered by QuickLaTeX.com")
 . This is equivalent to MTW’s Exercise 2.7 which uses Cartesian coordinates, after adjusting various minus signs because I use vectors not vector components. In terms of the 4-velocities alone, we have the curiously symmetric expression:
. This is equivalent to MTW’s Exercise 2.7 which uses Cartesian coordinates, after adjusting various minus signs because I use vectors not vector components. In terms of the 4-velocities alone, we have the curiously symmetric expression:![\[\boldsymbol\Lambda = \mathbf g^{\sharp\flat} + \frac{1}{\gamma+1} (\mathbf u+\mathbf n)\otimes(\mathbf u+\mathbf n)^\flat - 2\mathbf n\otimes\mathbf u^\flat.\]](http://cmaclaurin.com/cosmos/wp-content/ql-cache/quicklatex.com-31d4788ad546aeb17c52d153c53092e6_l3.png "Rendered by QuickLaTeX.com")
 has gradient
has gradient  , and the part of this which is orthogonal to an observer 4-velocity
, and the part of this which is orthogonal to an observer 4-velocity ![\[^{(3)}(d\Phi)^\sharp := (d\Phi)^\sharp + \langle d\Phi,\mathbf u\rangle \mathbf u.\]](http://cmaclaurin.com/cosmos/wp-content/ql-cache/quicklatex.com-9b0d26cd365bb242a44e935479e7df64_l3.png "Rendered by QuickLaTeX.com")
 is a null, future-pointing vector. It can be decomposed
is a null, future-pointing vector. It can be decomposed  , where
, where  , and
, and  is a unit spatial vector orthogonal to
is a unit spatial vector orthogonal to  , and to move in the spatial direction
, and to move in the spatial direction  , hence the direction of relative velocity also has the steepest increase of
, hence the direction of relative velocity also has the steepest increase of  , where
, where  is the
is the  , where
, where  is the relative velocity of
is the relative velocity of  . Hence within the observer’s 3-space,
. Hence within the observer’s 3-space, 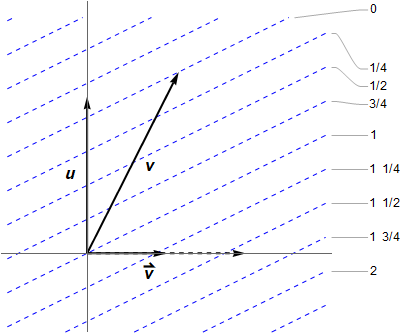
 is suggested by dotted blue lines, given at intervals of 1/4 for more resolution. These are orthogonal to the vector
is suggested by dotted blue lines, given at intervals of 1/4 for more resolution. These are orthogonal to the vector  , so
, so  . One can show
. One can show  . Also
. Also  , but I find it easier to think of:
, but I find it easier to think of:  . These give the number of hyperplanes crossed by the unit axes vectors, then you can literally “connect the dots” since the 1-form is linear. In the figure
. These give the number of hyperplanes crossed by the unit axes vectors, then you can literally “connect the dots” since the 1-form is linear. In the figure  , so
, so  . (As for the 3-gradient, it vanishes in the
. (As for the 3-gradient, it vanishes in the  . It would be drawn as vertical lines, with corresponding vector pointing to the right.)
. It would be drawn as vertical lines, with corresponding vector pointing to the right.) adapted to the observer, meaning
adapted to the observer, meaning  , and the
, and the  vectors are orthogonal to
vectors are orthogonal to  . Then a purely spatial vector is spanned by the
. Then a purely spatial vector is spanned by the  is the direction of steepest increase. We can mimic this mathematically by staying in 4 dimensions, but setting the “time” part to zero:
is the direction of steepest increase. We can mimic this mathematically by staying in 4 dimensions, but setting the “time” part to zero:![\[^{(3)}d\Phi := d\Phi + \langle d\Phi,\mathbf u\rangle \mathbf u^\flat.\]](http://cmaclaurin.com/cosmos/wp-content/ql-cache/quicklatex.com-07b08d0090362be83cad765ee6df27e8_l3.png "Rendered by QuickLaTeX.com")
 ” to imply it vanishes in the observer’s time direction. This “3-gradient” is the projection of
” to imply it vanishes in the observer’s time direction. This “3-gradient” is the projection of ![\[^{(3)}(d\Phi)^\sharp = (d\Phi)^\sharp + \langle d\Phi,\mathbf u\rangle \mathbf u.\]](http://cmaclaurin.com/cosmos/wp-content/ql-cache/quicklatex.com-f4c2ed9a3f4cd8007be9dd6c8b0433c1_l3.png "Rendered by QuickLaTeX.com")
 as usual. Note that on the subspace, the inverse metric coincides with the inverse 3-metric which has components
as usual. Note that on the subspace, the inverse metric coincides with the inverse 3-metric which has components  , for
, for  . Equivalently, one can apply the spatial projector
. Equivalently, one can apply the spatial projector  to either
to either  expresses the change in
expresses the change in ![\[\nabla_\mu\Phi = (d\Phi)_\mu = \Phi_{,\mu} := \frac{\partial\Phi}{\partial x^\mu}.\]](http://cmaclaurin.com/cosmos/wp-content/ql-cache/quicklatex.com-527fbdf54171e7f1dad06b04f9c48a61_l3.png "Rendered by QuickLaTeX.com")
 ” is called the exterior derivative, and
” is called the exterior derivative, and  , on the manifold (MTW
, on the manifold (MTW  . Given some vector
. Given some vector  , the contraction:
, the contraction:![\[d\Phi(\mathbf Y) \equiv \langle d\Phi,\mathbf Y\rangle = Y^\mu\frac{\partial\Phi}{\partial x^\mu}\]](http://cmaclaurin.com/cosmos/wp-content/ql-cache/quicklatex.com-6b2759547d61189d856872022a7d65aa_l3.png "Rendered by QuickLaTeX.com")
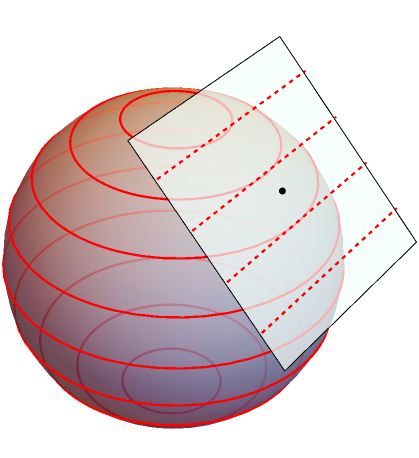
 , both over the entire manifold and within a single tangent space. The spacing is
, both over the entire manifold and within a single tangent space. The spacing is  .
. . This may be elegantly written
. This may be elegantly written  . By linearity, we need only consider unit vectors. The 1-form
. By linearity, we need only consider unit vectors. The 1-form  has components
has components  , with
, with  just
just  . These contract to give unity. If we restrict to vectors spanned by
. These contract to give unity. If we restrict to vectors spanned by  and
and  , Schutz’ steepness comments apply. However
, Schutz’ steepness comments apply. However  is also a unit spacelike vector, where
is also a unit spacelike vector, where  , hence crosses more intervals
, hence crosses more intervals  than the gradient vector does. Similarly for
than the gradient vector does. Similarly for  , the contraction with
, the contraction with  returns
returns  , but with the unit timelike vector
, but with the unit timelike vector  yields
yields  whenever
whenever  . The angle brackets mean contraction using the metric, with indices appropriately raised or lowered. Another property is the gradient vector’s squared-norm equals the 1-form’s squared-norm, which also matches the number of contours crossed:
. The angle brackets mean contraction using the metric, with indices appropriately raised or lowered. Another property is the gradient vector’s squared-norm equals the 1-form’s squared-norm, which also matches the number of contours crossed:![\[\langle (d\Phi)^\sharp,(d\Phi)^\sharp\rangle = \langle d\Phi,d\Phi\rangle = \langle d\Phi,(d\Phi)^\sharp\rangle.\]](http://cmaclaurin.com/cosmos/wp-content/ql-cache/quicklatex.com-e96c271c1bf8871402d5b158d940c579_l3.png "Rendered by QuickLaTeX.com")
 , for which the hyperplanes are spanned by vectors satisfying
, for which the hyperplanes are spanned by vectors satisfying  . For many creative illustrations see MTW, including their “honeycomb” and “egg crate” analogies for 2-forms and 3-forms, and their Figure 4.5 for the 2-form
. For many creative illustrations see MTW, including their “honeycomb” and “egg crate” analogies for 2-forms and 3-forms, and their Figure 4.5 for the 2-form  . Finally, I previously
. Finally, I previously  , which give the rate of change of the scalar by proper time along a worldline.
, which give the rate of change of the scalar by proper time along a worldline.